
2022年11月、OpenAIによってChatGPTが発表され、話題を席巻しています。あわせて世界的なビッグテックが次々と大規模言語モデル開発に参入し、目覚ましい技術発展が続いています。
2023年3月9日(木)に開催したJDLA緊急企画!「生成AIの衝撃」〜ChatGPTで世界はどう変わるのか〜では、松尾豊(JDLA理事長)、岡崎直観(JDLA有識者会員)、小島武(東京大学院博士課程)、清水亮(AI研究者)、川上登福(JDLA理事)に登壇していただき、「生成AI技術の正しい理解を踏まえ、ビジネスにどう活用するのか、日本として、自社として、個人として何をなすべきか」を参加者一人ひとりが考える契機となるようお話していただきました。

今何が起きているのか?|松尾豊教授

リリース後1週間で100万ユーザ、2ヶ月で1億ユーザに利用されているChatGPTの面白さは「技術の蓄積」と「社会的な相互総合作用による急激な普及」の二面性を持っていることです。
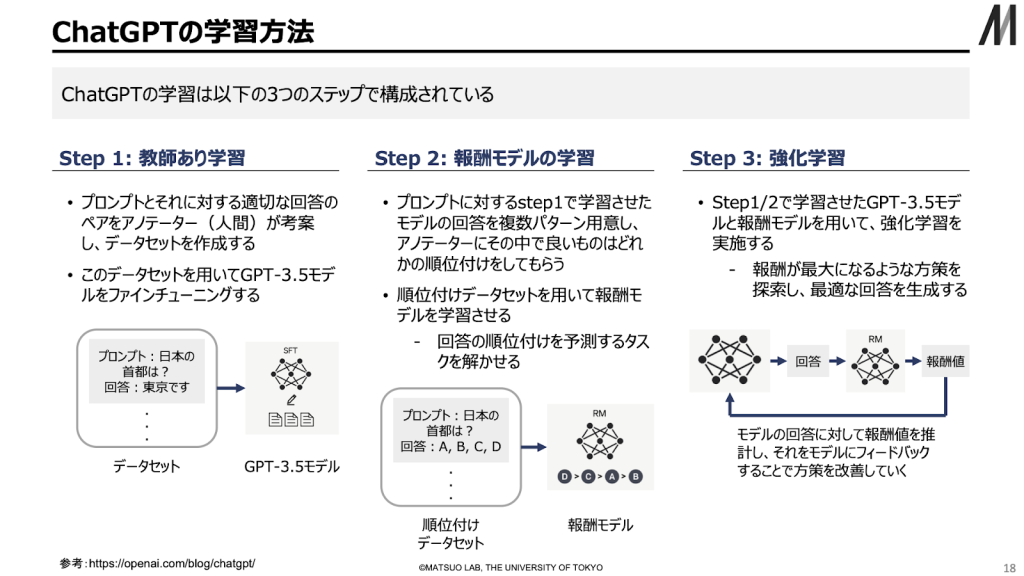
今までの対話AIは、登場するたびにユーザの悪戯によって失言をしてしまい、炎上してサービス停止になることもありました。それに対してChatGPTはRLHF(人間のフィードバックに基づいた強化学習)によって有害なテキストを生成させないように注意深く作られています。そのため、1億人のユーザがこれだけのペースで利用しても問題を起こすことなく、多くの人が新しい使い方を模索し、それがまた、新しい使い方を生み出すという社会的な現象になったと考えられます。
ChatGPTの登場によって長期的には「検索」がなくなっていくと思われます。また、Word、ExcelなどのOffice製品がさらなる進化を遂げ、人間が一言一句文字を打つという時代は過去のものになると考えられます。また、(OpenAIに莫大な投資をしている)マイクロソフト社の立場が圧倒的に有利になると考えられ、その他の世界的ビッグテックの主力事業が揺らぎかねないということで、歴史的現象だと思います。
今後、今のような汎用ツールとは別に、目的に特化したものも誕生すると考えられます。現在のChatGPTは有害なテキストを生成させないように学習させています。この学習方法を専門的なものに変えることで、医学や法学の知見から正しいコメントができるChatGPTができます。また、現在のChatGPTは感情を煽らないように設計していますが、逆に感情を煽るように設計すると相手を励ましたり、慰めるようなことも可能になると考えられます。2、3年もしないうちに全ての仕事に対して影響を与え始める可能性もあると考えており、近年第3次AIブームだと言われていますが、冬の時代を経ずに第4次AIブームに入ったのかもしれないと思っております。
大規模言語モデルの進展|岡崎直観教授
言語モデルとは、条件付き確率の積を用いてテキストの続きを推定するモデルです。このモデルは機械翻訳や音声認識において、単語の並びの自然さを考慮するために用いられてきました。
GPTはデコーダ(単語を予測する部分)に大規模なテキストを学習させ、最適な単語を予測できるようベクトルを近づけるよう学習させ、パラメータを更新させます。GPT3は1750億のパラメータを持ち、これを利用して言語に関する一般的な知識を言語モデルとして学習させます。そして、特定のタスクを解けるように事前学習済みのモデルをファインチューニングすることで、さまざまなタスクにおいて最高性能を達成させることができるようになりました。
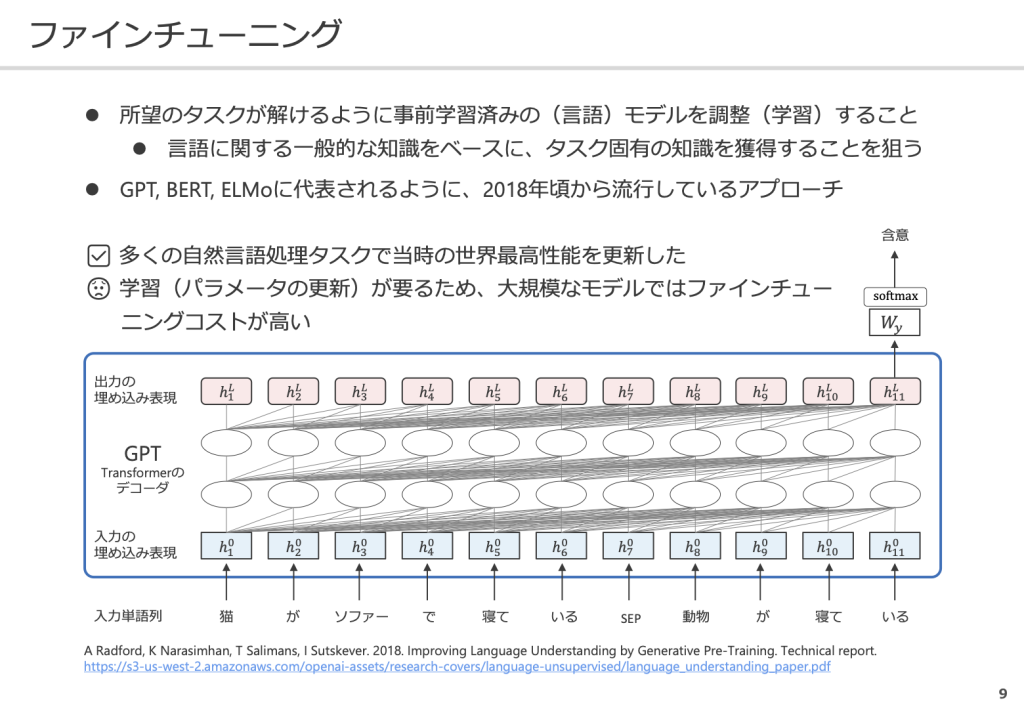
しかし、大規模なモデルでは、ファインチューニングにコストがかかってしまうため、ファインチューニングをしないでいろんなタスクを解けないかを考えたのがGPT2、GPT3です。
大規模言語モデルに与えるテキストを工夫し、タスクの解き方をテキストで学習させることでモデルのパラメータを更新することなく、言語モデルが汎用的に振る舞えるようになりました。しかし、ファインチューニングを行った場合と比較すると、タスクの性能が少し低いことがあるため、改善の余地はあると考えられます。
ChatGPTは学習データをテキストで読める形に変換した後にモデルとして学習させており、人間と流暢に対話できるような人工知能になりました。しかし、流暢な生成結果の中にも嘘が混入することがあるため、どのように対策するのかが今後の課題になると思います。また、著作権や公平性など以前から懸念された状況が現実を帯びるような時代になってきたと考えており、今後どのように解決するのか注目しています。
大規模言語モデルによる”思考の連鎖”|小島武さん

思考の連鎖とは最終的な答えに至るための自然言語による一連の中間的な推論ステップのことを指します。
例えば、以下のような問題があるとします。
大道芸人は16個のボールをジャグリングできます。そのうちの半数はゴルフボールで、さらにその半数は青色です。青いゴルフボールはいくつあるでしょう。
この問題の答えは4となりますが、答えに至るまで16÷2÷2=4という中間的な推論を行ったと思います。これが思考の連鎖という定義です。
思考の連鎖の重要性について「精度の向上」「説明可能性」の2つを紹介させていただきます。思考の連鎖を行うことで複雑な問題に対して直感的に答えるよりも精度が上がります。また、時には結論よりも過程が重要な問題もあり、思考の連鎖を振り返ることによって、どのような理由で結論に至ったのか理由を把握することができます。
このように、思考の連鎖連載には大きな重要性とメリットがあり、AIにも人間と同じように思考の連鎖ができることは素晴らしいことです。実際に大規模言語モデルにも人間と同じような思考の連鎖を行えるのか先程の大道芸人問題を大規模言語モデルに答えさせてみます。
先程の問題文をそのまま大規模言語モデルに解答させた結果、8という結果が返ってきます。
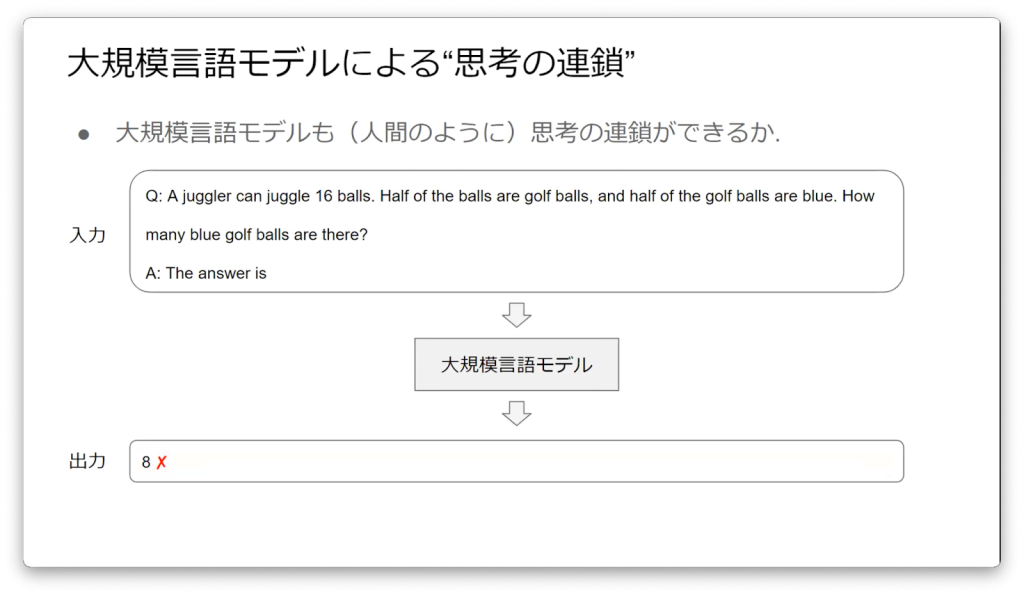
これに対して「一歩一歩考えてみよう」というフレーズを加え、もう一度解答させると4という結果が返ってくるようになり、思考の連鎖が行われました。

これに対して小規模言語モデルに「一歩一歩考えてみよう」というフレーズを加え、解答させても思考の連鎖は起きず、間違った解答が返ってくるようになります。これによって思考の連載にはモデルの規模が重要だと考えられます。
どうしてAIが思考の連鎖を行うことが可能なのかその原理は現時点では明確に答えることはできません。一方、思考の連鎖の有用性に着目して既に多くの発展的な研究が進められています。今回はその中の一つである「外部知識との接続」について紹介したいと思います。
学習済みの大規模言語モデルですが、膨大な知識を記憶している反面、知識が学習時のデータに依存するため、最新ではなかったり、間違えたりするリスクがあります。そこで、必要な知識を外部から取り込みながら思考の連鎖を行う手段が提案されています。
大規模言語モデルの発展が進むにつれ、AIの思考能力も飛躍的に高まり、近年のAI発展のブレイクスルーの一つだと考えております。思考の連鎖がうまくいく原理は現時点でわからないことも多く、解明の途中ですが、思考の連鎖を活用した発展研究は去年から著しいものがあり、その傾向は今後もしばらく続くと思われます。みなさんも思考の連鎖に興味を持ったいただけると幸いです。
コンシューマサービスとしての生成AI|清水亮さん
私はChatGPTで起こっている現象は一種のワイゼンバウム症候群だと考えています。半世紀ほど前にELIZAが登場し、多くの人は高度な知性を持ち、非常に役立つものだと誤解されることがありました。しかし、ELIZAは単なるパターンマッチのトリックに過ぎず、現代のTransfomer(GPT)もパターンマッチを自動的に獲得する手段に過ぎないため、AIが意味を理解しているわけではないと考えられます。
※ワイゼンバウム症候群:相手がコンピューターだとわかっていても、無意識にコンピュータが人間と似た動機があるように感じてしまう現象
※ELIZA:ジョセフ・ワイゼンバウムによって開発された初期の自然言語処理プログラム
大量の計算量、データ量、パラメータ量がある方が良いということはありますが、実際のデータを見ると幼稚園生や小学生が解く低いレベルの問題です。また、GPTシリーズは正解のある問題しか解いたことがないため、お金を儲けることはまだまだ難しいと思います。知的生産性を上げるものというのは正解のない問題の世界だと考えており、ここを突破するものを「ディスラプトAI」と私は呼んでいます。
ChatGPTやLangChainはGPTに強化学習や連鎖を掛け合わせているため、GPTシリーズとは進化軸が異なり、良い路線を進んでいるのではないかと思っております。
※LangChain:大規模言語モデルを用いてサービスを開発するライブラリ
2012年にディープラーニングが注目されていた時代、大学や研究機関ぐらいしかディープラーニングを利用していませんでしたが、その後大企業に次々とAIが活用されるようになり、最近では一般の人でも活用できるようになってきました。このようにテクノロジーは必ず小さく、安価になっていき、民主化されるまであまり時間を必要としていないのが歴史を見てもわかります。
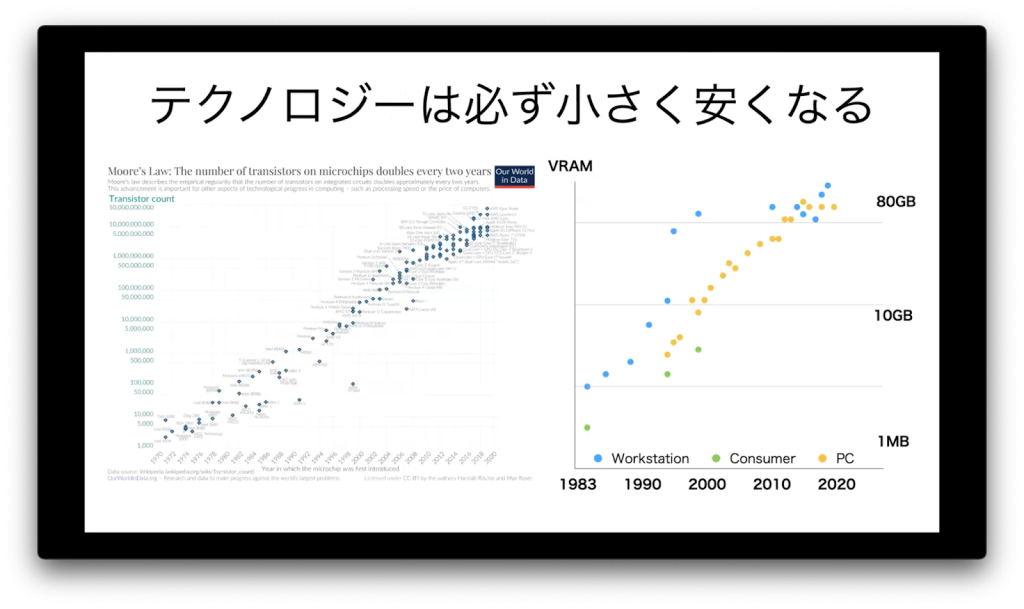
今まさに私たちはテクノロジーの民主化が進んでいる面白い時代を生きていると思います。
生成AIがビジネスに与える影響|川上登福さん
ChatGPTがここまで話題になった理由は「簡単に利用できて、役に立つ」だと思います。ChatGPTは使える人を限っておらず、使える場面も限られていないため、ユーザ数1億人まで普及したと考えられます。
実際にChatGPTが、どのようにビジネスに影響を与えるのか考えていきます。基本的に仕事というのはインプットを加工して付加価値を付けアウトプットすることです。ChatGPTを活用することで初期的なリサーチに必要とする時間を短縮することができるようになります。
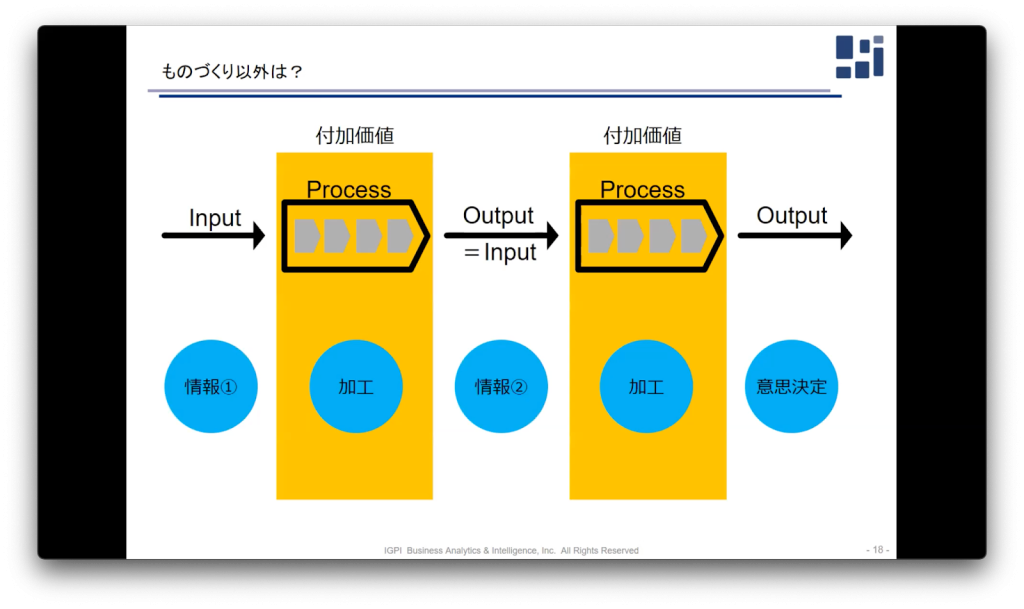
また、会話調で検索できるようになるため、顧客とのインターフェースも変化していくと考えられます。その上で情報取得のみならず、前工程と後工程を繋げることも可能だと考えており、フレキシビリティを持った意思決定もできるようになると考えています。
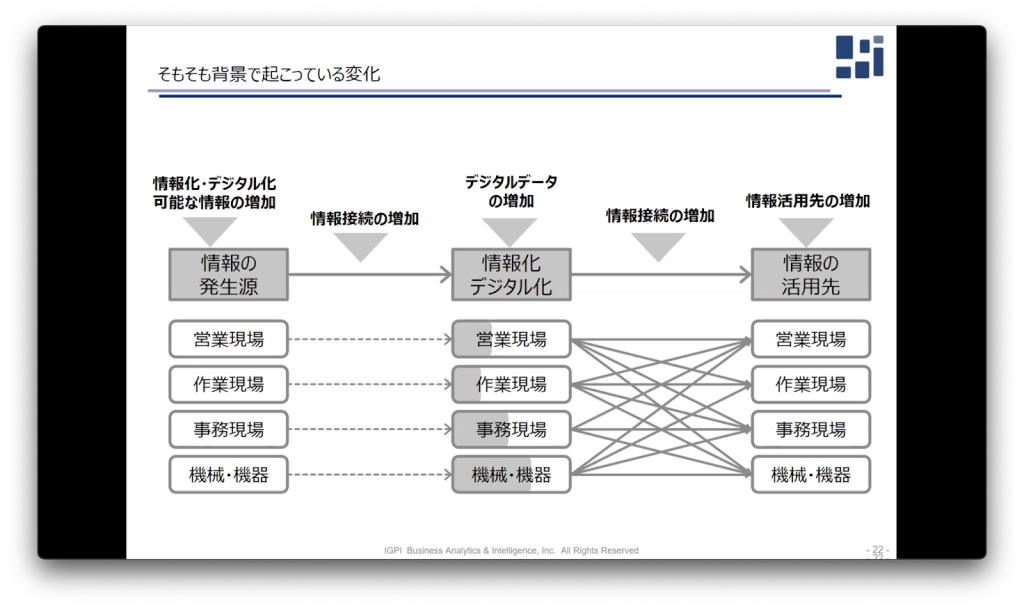
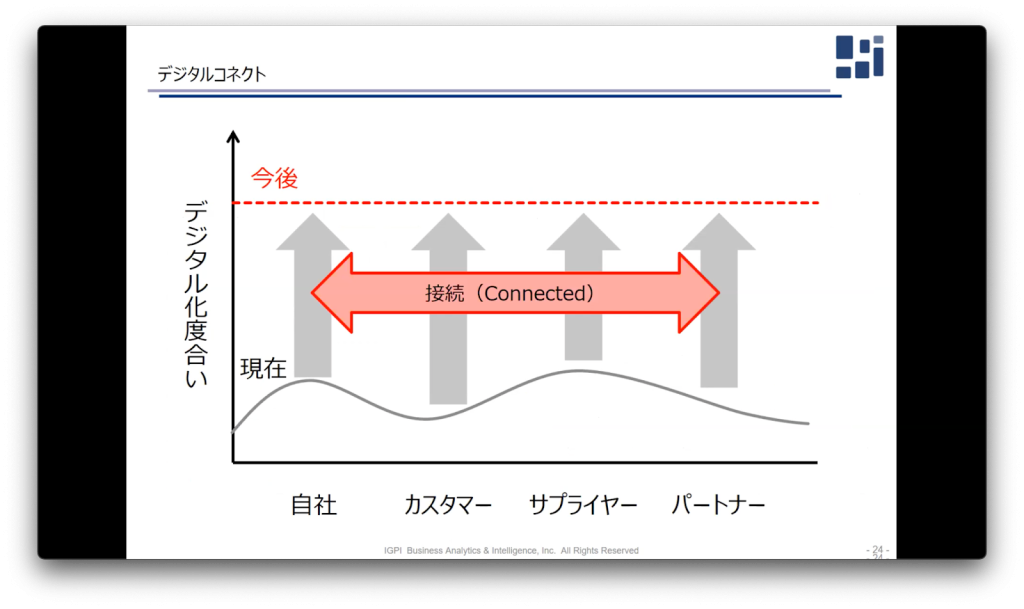
ChatGPTをビジネス活用するにおいて解決すべき課題は、技術的な問題よりも活用の仕方だと考えております。技術的限界は必ずありますので、現段階でできることを明らかにし、どのように使いこなすかを考えるべきです。また、情報加工業のコスト構造と、機能の再定義が必要だと考えています。近年デジタルデータが増加しており、これらをどう処理するかが求められています。今後自社だけではなく、他社の情報との接続することが大事だと言われており、その役目を大規模言語モデルが担っていくのではないかと考えています。
人間は五感を利用し情報処理判断をして活動しています。その中でも情報の伝達性では言語が圧倒的に適しています。大規模言語モデルが発展するにつれ、情報を言語を用いて処理・伝達することが可能になったため、大きなインパクトを持っていると思います。今後ビジネス視点で求められてくるのは「活用の創造性」と「実現するための行動力」です。この2つの要素が今まで以上にスピード高く求められると考えます。
パネルディスカッション
モデレーター林:近年の生成系AI技術の進展は非常に激しいものがあります。今後の技術発展についてコメントお願いします。
松尾:技術発展の速度には目を見張るものがありますが、それ以上に非常に使いやすくなったと思います。今までのAIシステムは使いにくく、SaaSにおいてもAI的な要素はほとんど入っていないようなサービスもたくさんありました。それに比べるとGPT3やChatGPTは非常に汎用性が高くなってきたと思います。
岡崎:会話でタスクを指示できるようになったことが面白いところだと思います。今まではタスク専用のモデルを作ることが主流でしたが、指示の仕方を調整しながら利用できるようになったのでユーザが馴染み深いAIシステムになっていると思っています。
小島:近年の大規模言語モデルのすごいところは、非常に長いプロンプトを最後まで一貫性を持って解答してくれるところです。今後文章が長くなると思うので、さまざまな問題に対して取り組めるようになると思います。
モデレーター林:技術の進展を踏まえてビジネスにどう活用していくかも重要なポイントになると考えられます。生成物の著作権などさまざまな問題にどう向き合っていくのかコメントお願いします。
清水:日本においてAIは学習し放題であることが一番大事なポイントだと思います。日本は漫画家など著作権者が非常に多い国なので著作法に対してケアすれば大丈夫というわけではなく、パブリシティ権などが考慮すべきところが多いです。むしろ、著作権に関しては基本的に議論の余地はなく、パブリシティ権や商標権を侵害しているか否かが議論されます。そのため、写真の大きさや記事の内容などを比較検討し、著名性がどこまで活用されており、どれほど独立性があるのかが議論されていくと思います。
モデレーター林:今後世界はどう変わっていくと思いますか?
清水:実は今、Web上で誰もがアクセスできる情報は減少しており、お金を払わないとアクセスできない情報が増えてきております。そうするとGPTシリーズに有益な情報を学習させてしまうと本来ならマネタイズできる情報を無料で世界中に公開してしまうことになり、損してしまいます。実際にメディアの人たちもGPTシリーズに学習データを提供することをやめようという流れが生まれています。そうすると大規模言語モデルに学習させるデータの質というのは下がり、モデル自体が馬鹿になることが予測できます。
岡崎:清水さんのご指摘の可能性もあると思います。一方でAIの学習データの中にはデータオギュメンテーションと言って自動生成しているものもかなりあるのが現状です。それでも性能自体は上がっているのも現状です。そのため、しばらくは人間によるChatGPTを活用したデータオギュメンテーションが続くのではないかと思います。
清水:我々は今現在岐路にたっていると思います。昔はコンピュータが素朴なものだったため、ELIZAのようなものが登場してもそこまで大きな影響はありませんでしたが、今は世の中にインターネットが普及しています。もし、ニュースアプリなどが影響を受けるとなると取り返しのつかない問題になりうるため、しっかり考慮すべきだと思います。
小島:学習データに関してですが、ChatGPTが書いた文章かどうか検知する研究が進んでいるのも現状です。ただ、これはイタチごっこだと思っており、検知できなくなるような文章が生成されるようになり、それをまた検知できるようになるを繰り返していくと思います。このようなフィルタリングでゆくゆくは、学習データが綺麗になっていくことで改善できると考えています。
--最後に皆さんに向けてコメントお願いします。
松尾:本日はありがとうございました。登壇者の方も技術的にもビジネス的にも非常に面白いお話をしていただけたと思っております。先ほど清水さんがお話されていたように我々は今分岐点にいると思います。なのでみなさん、ぜひ大規模言語モデルをたくさん利用してみてください。自分で触ってみることで得られる情報も多く、多くの方が自分で意思決定することが未来に繋がっていくと私は思います。
本日はどうもありがとうございました。
