- 人工知能とは
- 人工知能をめぐる動向
- 機械学習の概要
- ディープラーニングの概要
- ディープラーニングの要素技術
- ディープラーニングの応用例
- AIの社会実装に向けて
- AIに必要な数理・統計知識
- AIに関する法律と契約
- AI倫理・AIガバナンス
人工知能とは
以下の文章を読み、空欄に最もよく当てはまる選択肢を1つ選べ
人工知能は有限の処理能力しかないため、現実に起こりうる問題すべてに対処することができない ( ) がある
A)フレーム問題
B)ブラックボックス問題
C)シンボルグラウンディング問題
D)最適化問題
G検定2024#4に出題された過去問題
人工知能をめぐる動向
AI研究には過去に2度のブームが起こり、現実的な進展が周囲の過剰な期待に追いつかず、それらのブームは終焉を迎えた。第2次AIブームで登場し、第1次AIブームの時代に比べて適用範囲は広がったものの、知識を明示的な形で記述することの難しさがネックとなってしまったものとして、最も適切な選択肢を1つ選べ
A)ディープラーニング
B)コグニティブコンピューティング
C)機械学習
D)エキスパートシステム
G検定2022#1に出題された過去問題
コンピュータによる画像中の物体認識の精度を競う国際コンテスト ILSVRC にて、2015年にMicrosoft社が開発し、人間に勝るとも劣らない認識率を示したと報告され大きな話題となったスキップ結合を特徴とするモデルとして、最も適切な選択肢を1つ選べ
A)ResNet
B)AlexNet
C)ZFNet
D)VGGNet
G検定2022#1に出題された過去問題
機械学習の概要
重回帰分析の例として、最も適切な選択肢を1つ選べ
A)今日の株価から明日の株価を予測し、その結果から明後日の株価を予測する
B)ポイントカードのユーザ情報に記録された購買記録から、顧客の嗜好性をグループ分けする
C)出店予定の小売店舗の売上高を、地域の人口、店舗面積、販売品目数から予測する
D)アンケートに含まれるたくさんの項目を2つの分析軸に集約して分析する
G検定2022#3に出題された過去問題
あなたは来月リリース予定のECサイトにおけるレコメンデーションエンジンの作成を任された。商品が多いので、サイトのリリース時点で使えるレコメンドを開始したいという要望を受けた。この時、良好な精度が期待できる手法として、最も適切な選択肢を 1 つ選べ
A)コンテンツベースフィルタリング
B)協調フィルタリング
C)主成分分析 (PCA)
D)クラスタリング
G検定2024#6に出題された過去問題
ディープラーニングの概要
カルバック・ライブラー情報量 (KL) に関する説明として、最も適切な選択肢を 1 つ選べ
A)2つの確率分布がどの程度異なるかを定量的に評価するための指標である。この指標は非対称であるため、分布Pから見たQと分布Qから見たPの距離は一致しない
B)2つの確率分布がどの程度異なるかを定量的に評価するための指標である。この指標は対称であるため、分布Pから見たQと分布Qから見たPの距離は一致する
C)1つの確率分布がどの程度一様分布に近いかを定量的に評価するための指標である
D)1つの確率分布がどの程度正規分布に近いかを定量的に評価するための指標である
G検定2024#6に出題された過去問題
ニューラルネットワークにおいて、どのような条件のときに勾配消失問題が起こりやすくなると考えられるか. 最も適切な選択肢を1つ選べ
A)使用している活性化関数の微分値が大きい
B)学習データの数が多い
C)バッチ正規化を行っている
D)ネットワークの層が深い
G検定2022#1に出題された過去問題
ディープラーニングの要素技術
畳み込みニューラルネットワーク (CNN) において、パディングの効果の説明として、最も適切な選択肢を1つ選べ
A)移動不変性を強化する
B)データの特定範囲の特徴を抽出する
C)特徴マップを小さくする
D)出力サイズを調整することができる
G検定2024#4に出題された過去問題
以下の文章を読み、空欄に最もよく当てはまる選択肢を1つ選べ
畳み込みニューラルネットワーク (CNN) の出力層で、全結合層に代わって、( ) が用いられるようになった結果、出力結果と特徴マップとの関連が強くなることでこれまでよりも解釈しやすくなった
A)グローバルアベレージプーリング (GAP)
B)最大値プーリング
C)平均値プーリング
D)サブサンプリング層
G検定2024#4に出題された過去問題
Paraphrasingに関する説明として、最も適切な選択肢を1つ選べ
A)テキストデータのスペルエラーをランダムに追加する手法である
B)テキストデータをシャッフルしてランダムな順序にする手法である
C)テキストデータの単語を同義語や言い換えによって変換する手法である
D)テキストデータの各単語をランダムに削除する手法である
G検定2024#6に出題された過去問題
ディープラーニングの応用例
ChatGPTのベースとなるGPTは、大規模なデータセットを用いることでモデルを大規模化できている。この前提となる法則として、最も適切な選択肢を1つ選べ
A)スケーリング則
B)正規化則
C)中心極限定理
D)マルコフ過程
G検定2024#4に出題された過去問題
以下の文章を読み、空欄に最もよく当てはまる選択肢を1つ選べ
エッジデバイスで深層学習モデルを動かすため、しばしば ( ) と呼ばれる、モデルの重みそれぞれをより少ないバイト数で表現するためのプロセスが取られることがある
A)量子化
B)プルーニング
C)蒸留
D)標準化
G検定2024#4に出題された過去問題
zero-shot Learningの説明として、最も適切な選択肢を1つ選べ
A)訓練データ内カテゴリの新しいサンプルを識別する機械学習の手法である
B)新しいクラスのデータに対して事前の学習なしに識別を行う機械学習の手法である
C)教師あり学習と強化学習の中間に位置する機械学習の手法である
D)訓練データに存在しないカテゴリのサンプルを用いて、パラメータの更新を行う機械学習の手法である
G検定2024#6に出題された過去問題
AIの社会実装に向けて
検証データにデータリーケージがあった場合の影響について述べたものとして、最も適切な選択肢を1つ選べ
A)検証時には精度が良かったが、実際に導入すると精度が悪くなる
B)一定以上、学習が継続できなくなる
C)過学習が起きやすくなる
D)学習にかかる時間が増加する
G検定2022#1に出題された過去問題
AIに必要な数理・統計知識
以下のあ、い、う、えの説明に適した名称の組み合わせとして、最も適切な選択肢を1つ選べ
( あ ) 相関の程度を表す指標
( い ) 他の変数の影響を除いた相関の程度を表す指標
( う ) 偏差積の全データについての平均
( え ) 偏差を2乗したものの平均
A)( あ ) 相関係数 ( い ) 偏相関係数 ( う ) 共分散 ( え ) 分散
B)( あ ) 偏相関係数 ( い ) 相関係数 ( う ) 共分散 ( え ) 分散
C)( あ ) 相関係数 ( い ) 偏相関係数 ( う ) 分散 ( え ) 共分散
D)( あ ) 偏相関係数 ( い ) 相関係数 ( う ) 分散 ( え ) 共分散
G検定2022#1に出題された過去問題
6面体のサイコロの出る目の確率が以下の式に従う場合の (x) の期待値として、最も適切な選択肢を1つ選べ
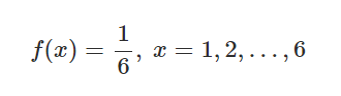
A)1
B)3
C)3.5
D)0
G検定2022#3に出題された過去問題
AIに関する法律と契約
個人情報保護法の説明として、最も不適切な選択肢を1つ選べ
A)メールアドレスのユーザー名及びドメイン名から特定の個人を識別することができる場合、そのメールアドレスは、それ自体が単独で個人情報に該当する
B)個人情報は新聞やインターネット等で既に公表されているとしても、個人情報保護法の保護の対象となり得る
C)外国に居住する外国人の個人情報は、個人情報保護法の保護の対象となり得る
D)顧客との電話の通話内容を録音したものは、通話内容から特定の個人を識別することができない場合、顧客IDなどで顧客データベースと突合する事が出来たとしても、個人情報に該当することはない
G検定2022#2に出題された過去問題
AIの開発契約において留意しなければならないこととして、最も不適切な選択肢を1つ選べ
A)アジャイル型の開発方式はあらゆる工程にすべてのステークホルダーが関与する余地があるため、仕様変更に柔軟に対応できる利点があるが、その分責任の範囲や成果の帰属について適時適切にコミュニケーションを取り、契約交渉を行うよう留意しなければならない
B)経済産業省の「AI・データの利用に関する契約ガイドライン」では、開発プロセスをアセスメント、PoC、 開発、追加学習の各段階に分けて、それぞれの段階で必要な契約を結ぶことで、試行錯誤しながら納得のゆくモデルを生成するアプローチがしやすくなるとしている
C)これまでの裁判例からシステム開発においては、開発者と利用者の双方に協力しあう義務があることが確認されており、そのなかには実際に発注を行う利用者が実際の業務や既存システムについて情報提供する義務も含まれている
D)契約交渉は実際の開発状況に合わせてステークホルダー間で適時適切なコミュニケーションを取りながら進めていく必要があるが、秘密保持契約はその内容上、開発の最終段階で結ぶことが望ましい
G検定2023#4に出題された過去問題
AI倫理・AIガバナンス
AIを用いた顔認識技術については、近年様々な倫理的な問題が指摘されている。この点に関して、最も不適切な選択肢を1つ選べ
A)顔認識技術については、肌の色が濃い人や女性において認識精度が下がるサービスが存在すると指摘されている. この原因として、学習に用いたデータセットの偏りが指摘されている
B)顔認識技術の利用にあたっては日本では個人情報保護法を遵守する必要があるが、それだけではなくプライバシーの観点から同法を超えた対応や措置を実施することが重要な場合がある。このような対応や措置の参考として、経済産業省が公表する「カメラ画像利活用ガイドブック」が存在する
C)IBM 社は 2020年6月に、顔認識技術を利用することの倫理的課題などを原因として、今後警察に汎用顔認識技術の提供を行わないことを表明した
D)アメリカでは都市によっては条例等により顔認識システムの利用を禁止しているが、その禁止対象は民間企業による利用ばかりではなく、警察などの公共性の高い公的機関による利用も含めるものが主流である
G検定2022#1に出題された過去問題
AIが与える地球環境への影響などのAIにおけるサステナビリティ上の課題について、最も不適切な選択肢を1つ選べ
A)モデルの巨大化・複雑化に伴い学習に必要な電力の増大がサステナビリティの点から問題となっている
B)運搬などの分野で効率の良い経路を導き出すことで、運搬によるエネルギー消費を抑えるというAIを用いた環境保護の取り組みが存在する
C)AIに多数のデータを学習させることは、学習効率が向上するため、電力消費量が少数データの学習の場合に比べて低下する
D)AIの学習や推論により発生する電力消費を抑えるべく、環境負荷の少ないモデルの開発が進められている
G検定2024#4に出題された過去問題
正解
(Q1)A、(Q2)D、(Q3)A、(Q4)C、(Q5)A、
(Q6)A、(Q7)D、(Q8)D、(Q9)A、(Q10)C、
(Q11)A、(Q12)A、(Q13)B、(Q14)A、(Q15)A、
(Q16)C、(Q17)D、(Q18)D、(Q19)D、(Q20)C

ディープラーニングの基礎知識と
事業活用能力を検定する資格試験


ディープラーニングの理論の理解と
開発実装能力を認定する資格試験


生成AIに特化した知識や活用リテラシーの確認の為のミニテスト

